

Understanding the Nature of Data Around Us
Structured, Unstructured and Semi-Structured Data

In the current paradigm, data is the new oil and it requires mining & exploration to make it valuable. Collecting data through observation & experimentation is the crucible that defines scientific thinking. Data points of occurrences, characteristics or experiences form the basis of how machines learn using algorithms today.
The key aspect of collecting data is identifying patterns, hence similar to math or rules of grammar. Patterns, once known can be replicated for similar future results. Hence pattern recognition from existing data helps in predicting future occurrences.
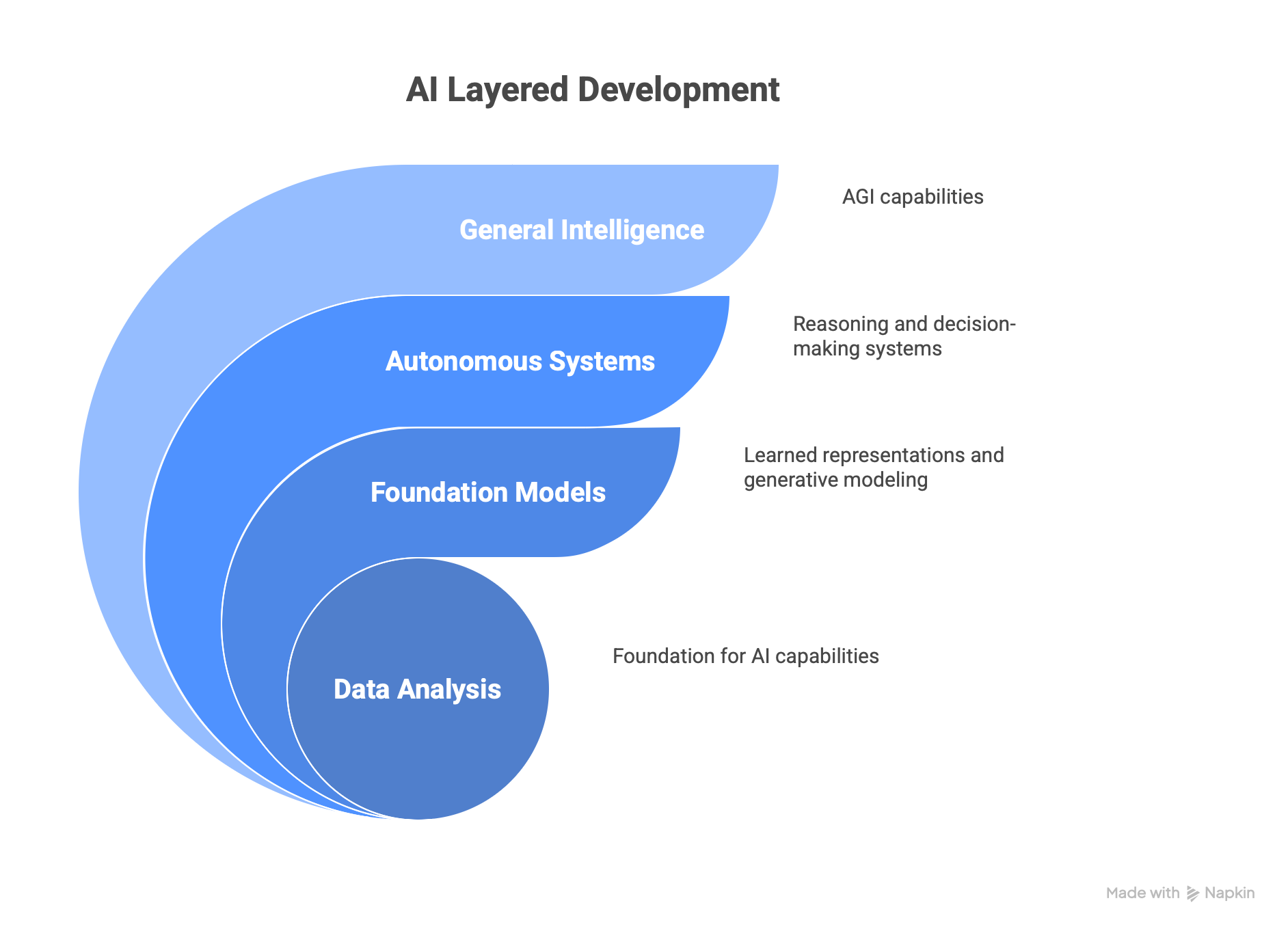
What is Data?
To harness this digital oil effectively, we must first understand its fundamental nature. Data refers to facts, figures, or information collected for analysis. It represents observations or measurements that can be processed to extract insights, make decisions, or build models. Data can exist in various forms like numbers, text, images, or sounds.
Understanding data as a scientific tool is the skill that's fundamental to learning AI/ML development models, thereby its systems. Just as oil exists in different geological formations requiring different extraction methods, data comes in various forms and shapes, each demanding unique analytical approaches.
Examples of data as pattern repositories:
Stock market fluctuations revealing economic cycles
Weather measurements showing seasonal patterns
Customer behavior data indicating purchasing trends
Medical records exposing disease progression patterns
Social media interactions demonstrating communication patterns
Three Data Types
Data manifests in three fundamental architectures, each requiring different extraction and refinement techniques.
1. Structured Data
Structured data represents the most refined form of information organization, following strict organizational principles with precise, predictable rules.
Predictable format enables algorithmic pattern detection, allowing systems to automatically identify recurring structures and anomalies within the data. Consistent schema allows for mathematical operations to be performed reliably across datasets, ensuring that calculations and transformations maintain their integrity. Tabular organization facilitates statistical analysis by providing a structured framework where variables can be easily compared and measured. Additionally, relationships between data points are explicitly defined, making it possible to trace connections and dependencies throughout the entire dataset.
Real-world Example:
Consider how structured data reveals patterns in customer behavior through organized transaction records:
Customer Transaction Patterns:
Customer_ID | Purchase_Date | Amount | Product_Category | Season
001 | 2024-01-15 | $150.00 | Electronics | Winter
001 | 2024-03-20 | $85.50 | Clothing | Spring
001 | 2024-07-10 | $220.00 | Sports | Summer
This structure reveals purchasing seasonality patterns - a machine learning algorithm can identify that Customer 001 increases spending in summer months, enabling predictive models for inventory and marketing.
2. Unstructured Data
Unstructured data represents information in its most natural, human-generated form. Like studying animal behavior in the wild rather than in controlled laboratory conditions, unstructured data captures the complexity and richness of real-world phenomena. This natural complexity presents unique analytical challenges that mirror the unpredictable nature of organic information flow.
Patterns exist in unstructured data but are embedded within intricate contexts, making them difficult to isolate and analyze without considering the surrounding environmental factors. Multiple pattern types can coexist in single data points, creating layered complexity where different analytical approaches may be needed to uncover each distinct pattern.
This multifaceted nature requires sophisticated algorithms to extract meaningful information, as traditional simple pattern matching techniques often prove inadequate for such elaborate data structures. Furthermore, the data contains both explicit and implicit information patterns, where some relationships are clearly visible while others remain hidden beneath the surface, requiring deeper analytical techniques to reveal their significance.
Mining unstructured data is like an exploration - valuable insights are buried beneath layers of complexity. Each document, image, or conversation contains multiple pattern layers that sophisticated AI systems can now excavate and analyze.
Examples of Hidden Patterns:
The complexity of unstructured data becomes evident when analyzing customer feedback:
Customer Review Analysis:
"This smartphone camera is incredible! Battery life could be better though.
After 6 months of heavy usage, still works great. Would recommend for photography
enthusiasts but maybe not for heavy gamers due to heating issues."Extractable Patterns:
Sentiment: Mixed (positive camera, negative battery)
Product lifecycle: 6-month durability confirmed
Product issues: Battery life and heating concerns
Recommendation pattern: Conditional endorsement
3. Semi-Structured Data
Semi-structured data represents a bridge between organized systems and natural complexity. Semi-structured data combines organizational elements with content variability such as an email or a log file entry below :
Server logs often follow patterns like:
[2024-08-24 14:30:15] ERROR user_id:12345 action:login_attempt ip:192.168.1.100 message:"Invalid password - 3rd attempt"
structured timestamp and fields, but flexible message content.This hybrid approach offers significant pattern recognition advantages. Structural tags provide navigation markers that help both systems and users locate specific information within the data, creating a roadmap through otherwise complex content. Content remains flexible for natural expression, allowing information to maintain its original context and meaning while still being organized in a systematic way.
This approach achieves machine-readable organization with human-readable content, striking an optimal balance where automated systems can process the data efficiently while humans can still interpret and understand it intuitively. This dual accessibility enables both automated and manual pattern analysis, giving researchers and analysts the flexibility to choose the most appropriate analytical approach based on their specific needs and objectives.
Key Insights
Data is pattern-rich information waiting to be discovered through systematic exploration
Different data types require different extraction techniques but serve the same pattern recognition purpose
Structured data provides immediate accessibility to pattern recognition algorithms
Unstructured data contains deeper insights but requires more sophisticated exploration methods
Semi-structured data offers balanced accessibility with rich contextual information.
Stay tuned for Part 2, where we'll uncover how proper organization and systematic analysis turn these data forms into the foundation of artificial intelligence.