


Python dictionaries are a compound data type designed to store and manage related data by mapping a custom index, called a key, to a corresponding value. This structure is analogous to a book dictionary that maps a word to its definition.
The need for dictionaries arises from the limitations of using lists for complex data storage. Let’s consider this with a student grades example:
Using parallel lists (one for names, one for grades) is cumbersome. To find a student’s grade, you first have to find their index in the
nameslist and then use that same index to access thegradeslist. This process becomes increasingly messy as more data (like quiz or problem set scores) is added, requiring more parallel lists that must be kept in sync.Using a “master list” of nested lists also proves to be complex and hard to read, requiring nested loops to search for specific information.
Dictionaries solve this by providing a direct mapping from a key (e.g., a student’s name) to a value (e.g., their grade or a more complex data structure containing all their information). An entry in a dictionary is a key-value pair.

Creating, Accessing, and Modifying Dictionaries
Creation
Dictionaries are created using curly braces
{}. An empty dictionary is created withd = {}.Entries are defined as
key: value, and multiple entries are separated by commas. For example, a dictionary mapping names to grades could be created like this:grades = {’Ana’: ‘B’, ‘Matt’: ‘A’, ‘John’: ‘B’}.
Accessing and Mutability
Dictionaries are mutable objects, meaning they can be changed after they are created.
To look up a value, you use the key as an index in square brackets, similar to list indexing (e.g.,
grades[’John’]would return‘B’).If you try to access a key that does not exist in the dictionary, Python will raise a
KeyErrorexception.You cannot look up a key by its value directly, as values can be duplicated. You would need to write a loop to perform this reverse lookup.
Operations
Adding or Modifying Entries: The same syntax is used for both adding a new entry and changing an existing one. If the key does not exist, a new entry is created. If it does exist, its value is overwritten. For example,
grades[’Grace’] = ‘A’adds Grace, andgrades[’Grace’] = ‘C’later changes her grade.Deleting Entries: The
delkeyword is used to remove an entry, such asdel grades[’Ana’]. This mutates the original dictionary.Checking for a Key: The
inoperator checks for the existence of a key in a dictionary (e.g.,‘John’ in gradesreturnsTrue). It is important to note that theinoperator only checks keys, not values.Copying: Since dictionaries are mutable, simple assignment (
d2 = d1) creates an alias (another name for the same object). To create a shallow copy, you must use the.copy()method (d2 = d1.copy()).
Iteration
While recent versions of Python guarantee insertion order for dictionaries, it is best practice to write code assuming they are unordered sequences for robustness and compatibility with older versions. There are three main ways to iterate over a dictionary:
.keys(): Returns an iterable sequence of all the keys in the dictionary..values(): Returns an iterable sequence of all the values..items(): This is often the most effective method, as it returns an iterable of key-value pairs as tuples. This allows you to access both the key and value simultaneously in a loop, for example:for k, v in my_dict.items():.
Restrictions on Keys and Values
Dictionary values can be of any type, including other mutable objects like lists or other dictionaries. Values can also be duplicated.
Dictionary keys have two main restrictions:
They must be unique. You cannot have two entries with the same key.
They must be immutable (technically, “hashable”). This means keys can be types like integers, floats, strings, tuples, and booleans, but cannot be lists or other dictionaries.
Performance and Implementation: Hashing
Following is a detailed explanation of why dictionaries offer superior performance for lookups compared to lists and why keys must be immutable :
Average-Case constant time lookup: Dictionaries are implemented using a hash table. A hash function is run on a key, which converts it into an integer. This integer is then used as a direct index to find the location of the corresponding value in the hash table (which is structured like a list in memory). Because this lookup is based on a direct calculation rather than a sequential search, accessing an item in a dictionary takes constant time (Θ
(1)) on average. This provides a massive performance advantage over searching a list, which takes linear time (Θ(n)).Collisions and worst-case performance: A “collision” occurs when two different keys produce the same hash value, mapping them to the same location or “bucket” in the hash table. These collisions are handled by storing the colliding entries together, often in a list-like structure within that bucket. A good hash function distributes keys uniformly, minimizing collisions. However, in the worst-case scenario, if all keys collide into the same bucket, looking up an item degrades to a linear search through that bucket, resulting in linear time (
theta(n)) performance.Why keys must be immutable: The hashing mechanism requires that a key always produces the same hash value. If a key were a mutable object like a list, its contents could change after it was stored in the dictionary. This change would alter its hash value, making it impossible for the dictionary to find the original location where the value was stored.
Use Cases
Storing Structured Data: Dictionaries are excellent for representing complex, structured data. The student information example was revisited to show how a nested dictionary (
grades[’Ana’][’ps’]) provides a much cleaner and more efficient way to store and retrieve data compared to nested lists.Counting Frequencies: A common pattern is to create a “frequency dictionary” to count occurrences of items. An example shows how to build a dictionary that maps each word in a song’s lyrics to the number of times it appears.
Memoization: Dictionaries are crucial for an optimization technique called memoization, which is used to speed up expensive computations, particularly in recursive functions. The Fibonacci example demonstrates this by storing previously calculated
fib(n)values in a dictionary. Before computing a value, the function checks if the result is already in the dictionary, avoiding redundant calculations. This improved the efficiency of the Fibonacci function from exponential time to a much faster one, reducing millions of function calls to just a few dozen.
Summary and Best Practices
Python dictionaries are the core tool for managing unordered, dynamic data that requires fast, key-based lookup. They fundamentally map unique, hashable keys to corresponding values.
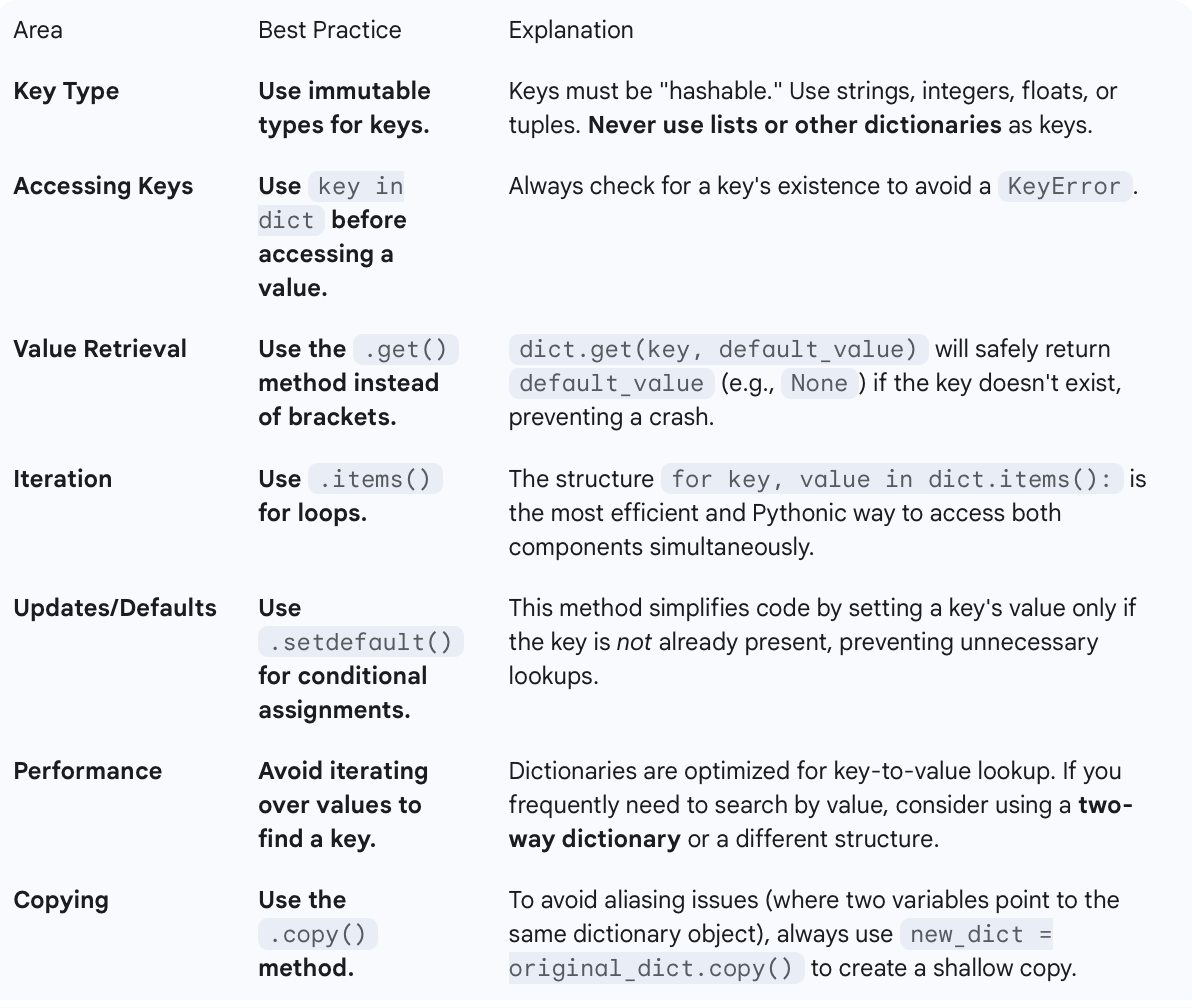
The dictionary’s defining characteristic is its reliance on hash tables, which allows for item retrieval in average-case constant time (Θ(1)), offering a massive performance advantage over sequential list searching.